搜索到
23
篇与
的结果
-
 aardio调用ChromeDriver系列范例 大家知道Chrome每个版本的适用ChromeDriver版本都不一样,安装不同的Chrome就要去下载不同的ChromeDriver.exe,而且还要命令行启动,绑定固定端口一搞不好还会跟别的进程冲突了。现在用aardio 最新版中提供的 chrome.driver 所有麻烦都可以解决了,chrome.driver 会自动查找Chrome的安装位置、版本号,自动匹配最合适的ChromeDriver版本,并且负责自动下载安装,自动分配空闲端口,所有事情全自动准备好,只要运行下面的代码就可以了。现在看代码,用法非常简单://WebDriver自动化 import chrome.driver; //创建chromeDriver对象 //协议文档 https://github.com/SeleniumHQ/selenium/wiki/JsonWireProtocol var driver = chrome.driver(); //创建会话,打开chrome浏览器,Chrome新版会强制显示控制台 var browser = driver.startBrowser(); //打开网页 browser.go("http://www.so.com") //查找文本输入框 var ele = browser.querySelector("#input"); //在网页输入框输入内容 ele.setValue( "ChromeDriver" ) //模拟点击按钮 browser.querySelector("#search-button").click();下面的问题在新版中已解决,可忽略:注意 Chrome新版会强制显示控制台( 隐藏也会强行弹出黑窗口,旧版可以隐藏这个黑窗口 ),如果想隐藏黑窗口,那么可以用旧版Chrome,在创建 chrome.driver对象时可以在参数中自定义chrome.exe的路径。调用 Electron也可以通过 ChromeDriver 调用 Electron,几句代码就可以了:import electron.driver; //创建chromeDriver对象,协议文档 var driver = electron.driver(); //替换electron默认的开始页 driver.addArguments("--app=http://www.so.com"); //创建会话,打开chrome浏览器,Chrome新版会强制显示控制台 var browser = driver.startBrowser(); //打开网页 //browser.go("http://www.so.com") //查找文本输入框 var ele = browser.querySelector("#input"); //在网页输入框输入内容 ele.setValue( "ChromeDriver" ) //模拟点击按钮 browser.querySelector("#search-button").click(); 修改 User Agent import chrome.driver; var driver = chrome.driver(); driver.addArguments("--user-agent=mychrome") //打开网页 driver.startBrowser().go("http://www.ip138.com/useragent/") chrome启动参数大全: 设置代理 import chrome.driver; var driver = chrome.driver(); driver.setProxy( proxyType = "manual"; httpProxy = "127.0.0.1:12043" ) 也可以下面这样写: import chrome.driver; var driver = chrome.driver(); var browser = driver.startBrowser( proxy ={ proxyType = "manual"; httpProxy = "127.0.0.1:12043" } );新版功能chrome.driver新版功能演示,操作chrome就像直接执行Javascript函数那么简单import chrome.driver; var driver = chrome.driver(); //启动浏览器 browser = driver.startBrowser(); //打开网页 browser.go("http://www.so.com") //查询元素,并且使用元素的querySelector函数查询子元素 browser.querySelector("body").querySelector("#input").setValue( "ChromeDriver" ) //模拟点击按钮 browser.querySelector("#search-button").click()隐藏控制台网上一些讨论认为这个问题无解,WebDriver也没有找到相关参数,直觉这个可能在启动参数里打开控制台,于是我写了一个假的 chrome.exe,再用 ChromeDriver.exe 调用他,代码如下:import console; import win.clip win.clip.write(_CMDLINE) console.log(_CMDLINE); console.pause();chrome.exe获得的启动参数如下:1 --disable-background-networking --disable-client-side-phishing-detection --disable-default-apps --disable-hang-monitor --disable-popup-blocking --disable-prompt-on-repost --disable-sync --disable-web-resources --enable-automation --enable-logging --force-fieldtrials=SiteIsolationExtensions/Control --ignore-certificate-errors --load-extension="C:\Users\***\AppData\Local\Temp\***\internal" --log-level=0 --metrics-recording-only --no-first-run --password-store=basic --remote-debugging-port=0 --test-type=webdriver --use-mock-keychain --user-data-dir="C:\Users\***\AppData\Local\Temp\***" data:,我们看到可疑参数--enable-logging,进一步测试发现:排除这个参数就可以关闭新版chrome启动跳出来的控制台窗口了,示例代码:import chrome.driver; var driver = chrome.driver( ); driver.setOptions( excludeSwitches ={"enable-logging"} //注意这里参数前千万不要加 -- ) driver.addArguments("--app=http://www.aardio.com") var browser = driver.startBrowser();已更新 chrome.driver 默认禁用控制台窗口,但仍然可以使用 driver.addArguments("--enable-logging") 启用这个参数。app、driver 交互aardio新版经过大力改进,现在 chrome.app, chrome.driver 已经可以相互结合使用,chrome与aardio交互更加简单方便。下面是一个简单的例子:import chrome.app; var app = chrome.app(); import chrome.driver; var driver = chrome.driver(); //指定允许chrome中使用JS直接调用的函数 app.external = { test = function(){ app.msgbox("页面js调用了aardio函数"); } } //正式的启动chrome进程 app.start("http://www.aardio.com",function(args){ //启动浏览器,加载aardio.js,并打开ChromeDriver自动化接口 var browser = driver.startAppBrowser(app,args); //执行JS脚本 browser.doScript(` document.addEventListener("click", function(event) { aardio.test(); }); `) return browser; }); win.loopMessage();禁用自动化测试提示方法一:import chrome.driver; var driver = chrome.driver(); driver.removeArguments("--enable-automation")虽然不显示上面的提示了,但是弹出一个更大的警告。方法二:import chrome.driver; var driver = chrome.driver(); driver.addArguments("--disable-infobars");不显示上面的提示,也没有警告了,但是可以看到提示框显示然后快速的关掉,会闪烁一下。方法三:import chrome.driver; var driver = chrome.driver(); driver.addArguments("--app=http://www.so.com/index.html");用–app模式的方法完美,地址栏、提示框、警告都去掉了,但是有一个奇怪的事情是,启动网址要写成 http://www.so.com/index.html 这样,如果不写 index.html 有时候会白屏,但不是每个网站都这样。清理临时文件Chrome每个进程只能绑定单独的用户目录 - 才能创建单独的远程调试端口,ChromeDriver 的办法是每次都创建一个临时的用户目录,然后每次都创建新的临时用户目录,而且又不负责删除(其实可以设置为重启系统自动删除,不知道Chrome为什么没有这么做),所以我们只好自己清理了,代码如下:import console; import fsys; fsys.enum( fsys.getTempDir(), "scoped_dir*_*", function(dir,filename,fullpath,findData){ if(!filename){ if( ..io.exist( io.joinpath(fullpath,"DevToolsActivePort") ) ){ fsys.delete(fullpath) } if( ..io.exist( io.joinpath(fullpath,"internal.zip") ) ){ fsys.delete(fullpath) } } },false ); console.pause(true);
aardio调用ChromeDriver系列范例 大家知道Chrome每个版本的适用ChromeDriver版本都不一样,安装不同的Chrome就要去下载不同的ChromeDriver.exe,而且还要命令行启动,绑定固定端口一搞不好还会跟别的进程冲突了。现在用aardio 最新版中提供的 chrome.driver 所有麻烦都可以解决了,chrome.driver 会自动查找Chrome的安装位置、版本号,自动匹配最合适的ChromeDriver版本,并且负责自动下载安装,自动分配空闲端口,所有事情全自动准备好,只要运行下面的代码就可以了。现在看代码,用法非常简单://WebDriver自动化 import chrome.driver; //创建chromeDriver对象 //协议文档 https://github.com/SeleniumHQ/selenium/wiki/JsonWireProtocol var driver = chrome.driver(); //创建会话,打开chrome浏览器,Chrome新版会强制显示控制台 var browser = driver.startBrowser(); //打开网页 browser.go("http://www.so.com") //查找文本输入框 var ele = browser.querySelector("#input"); //在网页输入框输入内容 ele.setValue( "ChromeDriver" ) //模拟点击按钮 browser.querySelector("#search-button").click();下面的问题在新版中已解决,可忽略:注意 Chrome新版会强制显示控制台( 隐藏也会强行弹出黑窗口,旧版可以隐藏这个黑窗口 ),如果想隐藏黑窗口,那么可以用旧版Chrome,在创建 chrome.driver对象时可以在参数中自定义chrome.exe的路径。调用 Electron也可以通过 ChromeDriver 调用 Electron,几句代码就可以了:import electron.driver; //创建chromeDriver对象,协议文档 var driver = electron.driver(); //替换electron默认的开始页 driver.addArguments("--app=http://www.so.com"); //创建会话,打开chrome浏览器,Chrome新版会强制显示控制台 var browser = driver.startBrowser(); //打开网页 //browser.go("http://www.so.com") //查找文本输入框 var ele = browser.querySelector("#input"); //在网页输入框输入内容 ele.setValue( "ChromeDriver" ) //模拟点击按钮 browser.querySelector("#search-button").click(); 修改 User Agent import chrome.driver; var driver = chrome.driver(); driver.addArguments("--user-agent=mychrome") //打开网页 driver.startBrowser().go("http://www.ip138.com/useragent/") chrome启动参数大全: 设置代理 import chrome.driver; var driver = chrome.driver(); driver.setProxy( proxyType = "manual"; httpProxy = "127.0.0.1:12043" ) 也可以下面这样写: import chrome.driver; var driver = chrome.driver(); var browser = driver.startBrowser( proxy ={ proxyType = "manual"; httpProxy = "127.0.0.1:12043" } );新版功能chrome.driver新版功能演示,操作chrome就像直接执行Javascript函数那么简单import chrome.driver; var driver = chrome.driver(); //启动浏览器 browser = driver.startBrowser(); //打开网页 browser.go("http://www.so.com") //查询元素,并且使用元素的querySelector函数查询子元素 browser.querySelector("body").querySelector("#input").setValue( "ChromeDriver" ) //模拟点击按钮 browser.querySelector("#search-button").click()隐藏控制台网上一些讨论认为这个问题无解,WebDriver也没有找到相关参数,直觉这个可能在启动参数里打开控制台,于是我写了一个假的 chrome.exe,再用 ChromeDriver.exe 调用他,代码如下:import console; import win.clip win.clip.write(_CMDLINE) console.log(_CMDLINE); console.pause();chrome.exe获得的启动参数如下:1 --disable-background-networking --disable-client-side-phishing-detection --disable-default-apps --disable-hang-monitor --disable-popup-blocking --disable-prompt-on-repost --disable-sync --disable-web-resources --enable-automation --enable-logging --force-fieldtrials=SiteIsolationExtensions/Control --ignore-certificate-errors --load-extension="C:\Users\***\AppData\Local\Temp\***\internal" --log-level=0 --metrics-recording-only --no-first-run --password-store=basic --remote-debugging-port=0 --test-type=webdriver --use-mock-keychain --user-data-dir="C:\Users\***\AppData\Local\Temp\***" data:,我们看到可疑参数--enable-logging,进一步测试发现:排除这个参数就可以关闭新版chrome启动跳出来的控制台窗口了,示例代码:import chrome.driver; var driver = chrome.driver( ); driver.setOptions( excludeSwitches ={"enable-logging"} //注意这里参数前千万不要加 -- ) driver.addArguments("--app=http://www.aardio.com") var browser = driver.startBrowser();已更新 chrome.driver 默认禁用控制台窗口,但仍然可以使用 driver.addArguments("--enable-logging") 启用这个参数。app、driver 交互aardio新版经过大力改进,现在 chrome.app, chrome.driver 已经可以相互结合使用,chrome与aardio交互更加简单方便。下面是一个简单的例子:import chrome.app; var app = chrome.app(); import chrome.driver; var driver = chrome.driver(); //指定允许chrome中使用JS直接调用的函数 app.external = { test = function(){ app.msgbox("页面js调用了aardio函数"); } } //正式的启动chrome进程 app.start("http://www.aardio.com",function(args){ //启动浏览器,加载aardio.js,并打开ChromeDriver自动化接口 var browser = driver.startAppBrowser(app,args); //执行JS脚本 browser.doScript(` document.addEventListener("click", function(event) { aardio.test(); }); `) return browser; }); win.loopMessage();禁用自动化测试提示方法一:import chrome.driver; var driver = chrome.driver(); driver.removeArguments("--enable-automation")虽然不显示上面的提示了,但是弹出一个更大的警告。方法二:import chrome.driver; var driver = chrome.driver(); driver.addArguments("--disable-infobars");不显示上面的提示,也没有警告了,但是可以看到提示框显示然后快速的关掉,会闪烁一下。方法三:import chrome.driver; var driver = chrome.driver(); driver.addArguments("--app=http://www.so.com/index.html");用–app模式的方法完美,地址栏、提示框、警告都去掉了,但是有一个奇怪的事情是,启动网址要写成 http://www.so.com/index.html 这样,如果不写 index.html 有时候会白屏,但不是每个网站都这样。清理临时文件Chrome每个进程只能绑定单独的用户目录 - 才能创建单独的远程调试端口,ChromeDriver 的办法是每次都创建一个临时的用户目录,然后每次都创建新的临时用户目录,而且又不负责删除(其实可以设置为重启系统自动删除,不知道Chrome为什么没有这么做),所以我们只好自己清理了,代码如下:import console; import fsys; fsys.enum( fsys.getTempDir(), "scoped_dir*_*", function(dir,filename,fullpath,findData){ if(!filename){ if( ..io.exist( io.joinpath(fullpath,"DevToolsActivePort") ) ){ fsys.delete(fullpath) } if( ..io.exist( io.joinpath(fullpath,"internal.zip") ) ){ fsys.delete(fullpath) } } },false ); console.pause(true); -
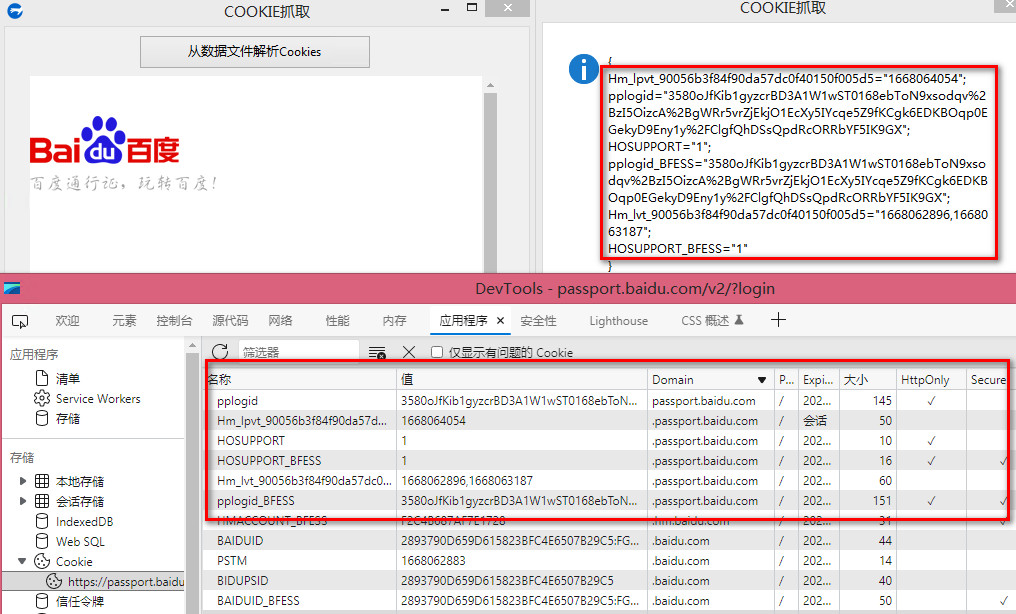
从Cookie本地文件里解密读取cookie值 HttpOnly是Cookie中一个属性,用于防止客户端脚本通过document.cookie属性访问Cookie,但毕竟Cookis是一种本地存储机制,全部的数据记录都存放在指定文件中(SQLITE格式,数值加密),所以可以解密此文件,用来获取到HttpOnly cookie等。代码以 WBVEIW 为例,也可以解密 chrome 和 chrome edge 浏览器的cookieimport win.ui; import crypt; import crypt.protectData; import web.json; import py3; import sqlite; /*DSG{{*/ mainForm = win.form(text="COOKIE抓取";right=523;bottom=541) mainForm.add( btnCookie={cls="button";text="从数据文件解析Cookies";left=134;top=8;right=366;bottom=42;z=2}; custom={cls="custom";text="自定义控件";left=25;top=49;right=494;bottom=528;z=1} ) /*}}*/ import web.view; var wb = web.view(mainForm.custom,"/"); wb.go("https://passport.baidu.com/") wb.wait(""); getCookie = function(){ var userDataPath = io.curDir() ++ "EBWebView\" // 1、从 EBWebView 文件夹下读取 Local State 文件中的encrypted_key值 var ekeyFile = io.open(userDataPath ++ "Local State","r+"); var ekeyArr = web.json.parse( ekeyFile.read() ); var base64_encrypted_key = ekeyArr.os_crypt.encrypted_key; //2 、 base64解码,DPAPI解密,得到真实的AESGCM key(bytes) var encrypted_key_with_header = crypt.decodeBin(base64_encrypted_key); var encrypted_key = string.trimleft(encrypted_key_with_header,"DPAPI"); var key = crypt.protectData.decrypt(encrypted_key,false); //3、AES-GCM解密,aardio未找到此函数,调用PY处理 pyCode = /** from cryptography.hazmat.primitives.ciphers.aead import AESGCM def DecryptString(key,data): nonce,cipherbytes=data[3:15],data[15:] aesgcm=AESGCM(key) plainbytes=aesgcm.decrypt(nonce,cipherbytes,None) plaintext=plainbytes.decode('utf-8') return plaintext **/ py3.exec(pyCode) //4、从SQLITE格式的COOKIES文件里读取数据 var db = sqlite(userDataPath ++ "Default\Network\Cookies"); var result = {}; var sqlStr = /* select name,encrypted_value from cookies where host_key like '%passport.baidu.com' */ for name,encrypted_value in db.each(sqlStr) { result[name] = tostring(py3.main.DecryptString(key,encrypted_value)); } return result; } mainForm.btnCookie.oncommand = function(id,event){ mainForm.msgbox( getCookie() ) } mainForm.show(); win.loopMessage();
-
一个有用的php函数:读取大文件最后几行记录 通常我们需要读取一些日志文件,但有时日志很大,有时记录的时间很长,我们只想看最新的最近的记录,这就需要从最后几行读取。这个函数就比较有用了。<?php /** * 取文件最后$n行 * @param string $file 文件路径 * @param int $line 最后几行 * @return mixed 成功则返回字符串 */ function getLastLines($file,$line=1){ if(!$fp=fopen($file,'r')){ echo "打开文件失败"; return false; } $pos = -2;//偏移量 $eof = " ";//行尾标识 $data = ""; while ($line > 0){//逐行遍历 while ($eof != "\n"){ //不是行尾 fseek($fp, $pos, SEEK_END);//fseek成功返回0,失败返回-1 $eof = fgetc($fp);//读取一个字符并赋给行尾标识 $pos--;//向前偏移 } $eof = " "; $data .= fgets($fp);//读取一行 $line--; } fclose($fp); return $data; }//测试代码print_r(getLastLines("access.log",5));exit;
-
关于 # tesseract #的使用 记得以前安装 tesseract的py库 tesseractocr很麻烦,装不上要装whl文件。现在,有了新库pytesseract,安装很简单。 安装 tesseract也是一路回车,记得选上中文库就行了。这里记录几个使用心得:1,经测试,3.5版,对中文的识别率感人,达不到实用要求。而使用 tesseract 4.0版,识别率则明显提升,只有少数错误。所以改用4.0。2,不过,3.5和4.0版有一个区别。3.5版的语言包路径,不能直接写 tessdata目录,而要设成它父目录。否则提示找不到语言包。而 4.0的路径TESSDATA_PREFIX 设置时则要指向tessdata目录。我将使用正常的3.5的删除重装4.0后,以前的环境配置下,提示找不到包文件,而目录指向ocr目录。 3,另外,环境变量改了后,在程序中运行并不能生效。重启电脑是不想重启的。退出当前py或者php环境,重新打开,就生效了。php的TesseractOCR,比py使用起来更简单。
-
科学文库PDF原文下载 引言因为学习的原因,在使用电子书籍的时候较多,所以有时候不得不在百度或者学校的图书馆搜一下书籍。当时找的是一本“数值分析”书籍,在百度没有找到,图书馆给我推荐到了一个文库,说可以看电子版的,但是不能下载。每次进入网站看很麻烦呀,而且提供的图片清晰度也不高,所以需要看看可不可以下载。部分打印通常的思路是看看网页pdf可不可以直接打印,如果可以直接打印的话,那么我们也就不需要多加步骤了。 图 1幸运的是,图1这里直接有打印的图标,但会发现,图2除了“当前页面”可选中之外,其他的按钮均为不可选中。因为这些属性是直接可以通过界面即网页源码定义的,所以通过检查元素图3或者F12开发者选项功能图4进行定位,则可以修改标签选中状态。 图 2 图 3图 4删除相关元素的disabled="disabled" 属性,则可以进行选中相关标签。但这里有一个问题是每次操作打印后,需要再进行上述操作,这是因为在网页再刷新的时候,js文件会再次进行属性设置,我们没有进行js文件修改,所以我们的操作会被覆盖。当选中“所有页面”时,如果电子书籍页码大于100页时,会提示我们超过了100页,会终止打印,下面两个“页面”设置如果超过100页也会这样提示,这个问题我们等会再进行处理。这里主要说的是多次部分小于100页的打印。所以每次按照上述操作,选中“页面”进行小于100页的多批次打印,打印的时间不确定,依照文件大小或者网络速度有关,因为在打印过程中,通过网络监控可以发现,打印的原理是进行图片链接访问,然后以图片的形式打印成pdf。这种方法会出现以下问题:1.图片的质量不高,默认的图片质量为100。2.打印的pdf文件为图片pdf,并不是矢量pdf。全文打印当我们选中“所有页面”打印的时候,会提示“当前设置的页面已超出范围”。所以我们就需要找到当我们点击“下一步”按钮时,按钮传递了什么值,为什么会提示(如图5) 图 5这里可以发现选中“所有页面”时,传递的value值为all。但是我们对按钮监听事件分析,并没有直接得出跟判断100页有关系的函数。所以转变一个思路,开始没有显示提示,但是超过100页会提示,所以这个显示与100页有关系。选中提示,得到提示的id为“lablePrintInfo”。所以进行搜索得到图6:图 6在18752行:B > 100)return void $("#lablePrintInfo").html(i18n.t("Print.OutOfRangeMessage"));var s = "";这里可以发现这里有一个判断,如果大于了100,则会提示,所以我们只需要修改这个100页为一个比较大的值,就可以实现全文打印了。(修改js文件方法自行百度)这里存在一个问题:打印的时间特别长且打印出来的格式容易错乱。清晰度设置打印的过程中会发起> “https://网站地址/asserts/书籍id/image/页码/分辨率?accessToken=accessToken&formMode=true“通过对‘formMode’搜索,可以找到:var e = a.getBaseUrl() + "asserts/" + a.getFileID() + "/image/" + b + "/100?formMode=false&accessToken=accessToken", f = new XMLHttpRequest;所以将100进行设置,可以提高图片的分辨率。此方法对于超级大型的文件并不适用,这里也不做过多讲解。全文下载既然我们可以直接浏览pdf,那么说明在访问这个网站的时候,系统需要传入或者设置pdf文件,pdf文件可以是本地也可以是网络文件。所以我们对网站再次刷新分析整个加载过程。在进程中发现存在一个post,名叫add。查看post表单:params:{"params":{"userName":"8","userId":"*","file":"*.pdf"}}type: *所以我们发现这实际上是将网络pdf文件加载出来的,但是我们直接访问pdf地址是没有权限的。而上面的post得到了一个result。再综合后面的一系列链接,发现result就是一个文件的id。但是我们要想办法使用这个id。在后面的链接中发现有一个info的get请求,它得到了assertUrl,fileid,fname,userName。这里我的第一个想法就是对得到的数据进行get,或许这样就可以得到pdf文件了。哎,但是无果,我怎么进行get拼接,都访问不成功。这里实在想不通了,我就直接不拼接了,将assertUrl的根网址访问了一下。居然,发现可以直接访问,可以是访问到了一个在线pdf阅读器,其中的界面与刚才的差不多,但是有许多功能可以直接使用。甚至有直接下载pdf的功能,但是点击“下载pdf”发现会下载失败。于是又看见有“开启离线阅读模式”功能,点击后会下载pdf文件;对下载文件地址分析:http:///api/file/*/getDocumentbufferSo 可以下载了